Does it Work and Why Does it Work?
Getting started
Starting out in R can be challenging. In this first session we’ll cover the absolute basics, however the examples and materials provided here are by no means comprehensive. For those who successfully completed EDP 611, please feel free to ignore this unless you would like a refresher.
| Level of Difficulty1 | Beginner |
| What You’ll Mainly Do | Type in syntax |
| Language(s) We’ll Use2 | |
| 1 This is not an indicator of your personal level or abilities. You may experience varying level of ease and/or difficulties and that is OK! | |
| 2 Hover over an icon to see its name |
Prerequisite
None
Materials
The following download contains files that are provided to help you to understand and/or complete the walkthrough.
Walkthrough
Set your Working Directory
Your working directory is simply where your script will look for anything it needs like external data sets. There are a few ways to go about doing this which we will cover. However for now, just do the following:
- Open up a new script by going to
File > New File > R Script. - Save it and any data like the
drinks.csvfile in a preferably empty folder and name it whatever you like. - Go to the menu bar and select
Session > Set Working Directory > To Source File Location.
In this session, we will expand on the the tidyverse family of packages along with some help using data from the site FiveThirtyEight using the aptly named package fivethirtyeight.
If you have already downloaded tidyverse, then please skip ahead to the next paragraph. If not, please do the following:
- select Tools > Install Packages
- type in tidyverse and make sure that Install dependencies is selected.
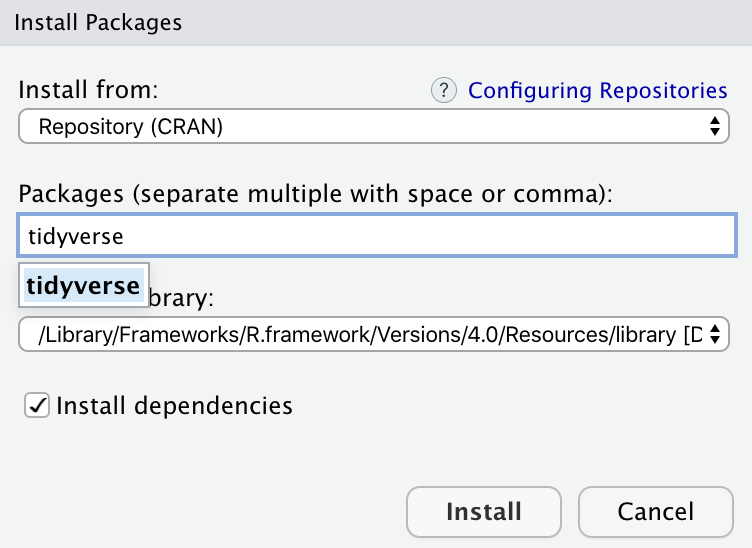
Alternatively, you can simply run the following command in the console
install.packages("tidyverse", dependencies = TRUE)
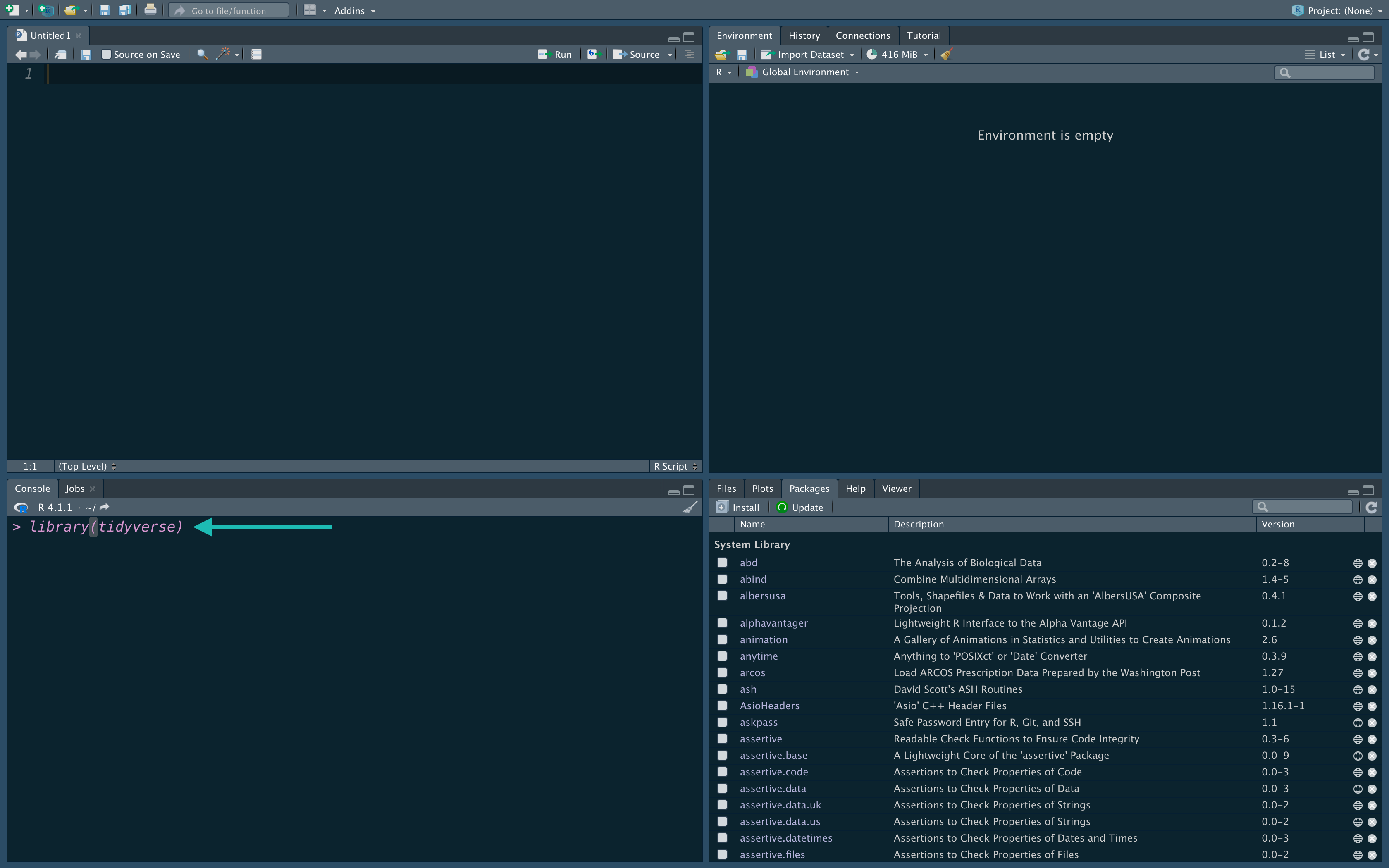
In either case, now load up the package by typing in following in the script area
library("tidyverse")
Now try doing the same for fivethirtyeight by running
install.packages("fivethirtyeight", dependencies = TRUE)
followed by
library("fivethirtyeight")
Please note that once a package is on your computer, you never have to install it again unless it is somehow deleted. This means from now on you will only have to use the second command library(“THAT PACKAGE”) to use that package.
Before moving on, here is a good place to reiterate how you can use ? to find more information. When you look at the package list for fivethirtyeight, not all of the names do a great job of describing what that data set consists of. To see this, type in fivethirtyeight:: and scroll through the pop up list of available data sets and commands. Let’s say the data set tarantino caught your eye but you weren’t really sure what it consisted of. Hovering over the set in that pop up list tells you that it contains data behind the story A Complete Catalog Of Every Time Someone Cursed Or Bled Out In A Quentin Tarantino Movie.
OK well that’s a good start but to be able to do anything with that data, we really need to know what its variables are. To do this, run the command below
?tarantino
You should have noticed the Help tab on the lower right hand window is prominent and there is a significant amount of information explaining the data set including the variable names and corresponding descriptions.
Data Files
Data sets used in R are typically accessible in three ways, through these certainly are not the only approaches.
| Approach | Description | Source | Command |
|---|---|---|---|
| Fetch | You can get grab files directly from the Internet.2 | drinks data | data(‘drinks’, package = ‘fivethirtyeight’)3 |
| Download | Used typically for examples, demonstartions and testing, many packages have data already included. | drinks data | drinks <- read_csv(‘drinks.csv’)4 |
| Extract1 | R specific file formats include .RData and .rda but it can load most, if not all types inlcuding popular choices such as a .csv, .xlsx, and .sav. | drinks data | drinks <- read_csv(‘https://raw.githubusercontent.com/fivethirtyeight/data/master/alcohol-consumption/drinks.csv’)4 |
| 1 If applicable | |||
| 2 You can also scrape tables off of webpages | |||
| 3 To see the entire list, you can run the command data() | |||
| 4 You can also use = instead of <- though that may get you into trouble later so it is not recommended |
In any case, type the following into your console and you should the following output regardless of approach taken
drinks
## # A tibble: 193 × 5
## country beer_servings spirit_servings wine_servings total_litres_…¹
## <chr> <int> <int> <int> <dbl>
## 1 Afghanistan 0 0 0 0
## 2 Albania 89 132 54 4.9
## 3 Algeria 25 0 14 0.7
## 4 Andorra 245 138 312 12.4
## 5 Angola 217 57 45 5.9
## 6 Antigua & Barbuda 102 128 45 4.9
## 7 Argentina 193 25 221 8.3
## 8 Armenia 21 179 11 3.8
## 9 Australia 261 72 212 10.4
## 10 Austria 279 75 191 9.7
## # … with 183 more rows, and abbreviated variable name
## # ¹total_litres_of_pure_alcohol
If you attempted to load the csv, then you may realize that RStudio puts up both read.csv() with a . and read_csv() with a _ as possibilities. The former is what we call a base command, or one that is pre-built into R. However, you will likely want to stick to the latter read_csv() which is from the readr package which is albeit faster and returns a tibble instead of a data frame. This is just a tidy data frame. You can check what type of variable you have by using class(VARIABLE NAME) on it. For example, the following
class(drinks)
## [1] "tbl_df" "tbl" "data.frame"
tells us that we not only have a data frame, but a tibble as well as well as some other formats we’ll ignore for the time being. If you want more information, please see Ch 10: Tibbles in R for Data Science.
Note that we loaded the file directly from a web address URL, but say you had it as a local file on your computer in the same directory as your R script. The commands
drinks <- read_csv("drinks.csv")
drinks
or
drinks <- read_csv("drinks.csv"); drinks
work just as well.
Chopping Up a Data Set
You may already know that the single bracket, [, is useful to select rows and columns in simple cases.
drinks[c(1, 2, 3, 4, 5), ]
## # A tibble: 5 × 5
## country beer_servings spirit_servings wine_servings total_litres_of_pure…¹
## <chr> <int> <int> <int> <dbl>
## 1 Afghanistan 0 0 0 0
## 2 Albania 89 132 54 4.9
## 3 Algeria 25 0 14 0.7
## 4 Andorra 245 138 312 12.4
## 5 Angola 217 57 45 5.9
## # … with abbreviated variable name ¹total_litres_of_pure_alcohol
There are tidyverse options to handle this via the package dplyr to select rows by number, to select rows by certain criteria, or to select columns.
For example, to select rows 1–5, we can use the slice() command.
slice(drinks, 1:5)
## # A tibble: 5 × 5
## country beer_servings spirit_servings wine_servings total_litres_of_pure…¹
## <chr> <int> <int> <int> <dbl>
## 1 Afghanistan 0 0 0 0
## 2 Albania 89 132 54 4.9
## 3 Algeria 25 0 14 0.7
## 4 Andorra 245 138 312 12.4
## 5 Angola 217 57 45 5.9
## # … with abbreviated variable name ¹total_litres_of_pure_alcohol
Base R allows you to choose the column beer_servings from the drinks data frame in a number of ways. For example, each of the following
drinks[, "beer_servings"]
drinks$beer_servings
drinks[["beer_servings"]]
yields
## [1] 0 89 25 245 217 102 193 21 261 279 21 122 42 0 143 142 295 263
## [19] 34 23 167 76 173 245 31 231 25 88 37 144 57 147 240 17 15 130
## [37] 79 159 1 76 0 149 230 93 192 361 0 32 224 15 52 193 162 6
## [55] 52 92 18 224 20 77 263 127 347 8 52 346 31 133 199 53 9 28
## [73] 93 1 69 234 233 9 5 0 9 313 63 85 82 77 6 124 58 21
## [91] 0 31 62 281 20 82 19 0 343 236 26 8 13 0 5 149 0 0
## [109] 98 238 62 0 77 31 12 47 5 376 49 5 251 203 78 3 42 188
## [127] 169 22 0 306 285 44 213 163 71 343 194 1 140 109 297 247 43 194
## [145] 171 120 105 0 56 0 9 283 157 25 60 196 270 56 0 225 284 16
## [163] 8 128 90 152 185 5 2 99 106 1 36 36 197 51 51 19 6 45
## [181] 206 16 219 36 249 115 25 21 333 111 6 32 64
Unlike [, the [[ and $ operators can only select a single column and return a vector.1
The dplyr function select() always returns a tibble, and never a vector, even if only one column is selected.
For example, note that selecting rows 1–5 of the beer_servings column using base R gives us a vector.
drinks[1:5, "beer_servings"]
## # A tibble: 5 × 1
## beer_servings
## <int>
## 1 0
## 2 89
## 3 25
## 4 245
## 5 217
Whereas in the dplyr world, the same series of functions can be performed using a pipe operator: %>% which retains the table like format.
drinks %>%
slice(1:5) %>%
select(beer_servings)
## # A tibble: 5 × 1
## beer_servings
## <int>
## 1 0
## 2 89
## 3 25
## 4 245
## 5 217
This example may seem verbose, but later we can produce more complicated transformations of the data by chaining together simple functions. For example, it is far easier to use them to select multiple columns like so
drinks %>%
slice(1:5) %>%
select(country, beer_servings)
## # A tibble: 5 × 2
## country beer_servings
## <chr> <int>
## 1 Afghanistan 0
## 2 Albania 89
## 3 Algeria 25
## 4 Andorra 245
## 5 Angola 217
or to get rid of a column
drinks %>%
slice(1:5) %>%
select(-spirit_servings)
## # A tibble: 5 × 4
## country beer_servings wine_servings total_litres_of_pure_alcohol
## <chr> <int> <int> <dbl>
## 1 Afghanistan 0 0 0
## 2 Albania 89 54 4.9
## 3 Algeria 25 14 0.7
## 4 Andorra 245 312 12.4
## 5 Angola 217 45 5.9
We’ll use pipes throughout the term!
Saving Objects
There are two types of saves you should consider at this point
- The workspace save
- An output save
The workspace save is everything you see in your RStudio window (e.g. the syntax, script, outputs, etc). When you close out of RStudio, you may be asked to save your workspace which essentially means the next time you load a saved script up, you’ll pick up exactly where you left off.
While convenient, it is not recommended that do this. Like rebooting a computer, you really want to have a fresh start every time RStudio starts up. While certainly not mandated, you never know what piece of rogue commands could have affected your progress when you last saved the file. Opting not to save an image of your workspace removes all of the previous commands while keeping your script intact.
An output save occurs when you are trying to save a data set or result in a particular format. Firstly, you have to ensure that you have both downloaded and loaded a necessary package.
Let’s say we want to export our drinks output to a csv file. Well luckily we have the package readr already loaded and it has the command write_csv() that does exactly what we want. The command requires that you note the variable name, drinks, and what you want to call it which in this case I am calling new_drinks.csv. If you are wondering, you absolutely have to write out the format type at the end which is a .csv in this case.
write_csv(drinks, "new_drinks.csv")
Well that’s great but say we wanted to save it as a SPSS file. Running
?write_csv
doesn’t yield any information about saving any data set or output as a SPSS file. If we run a simple Google search (e.g. with the terms save SPSS R tidy) and click on the first link, it seems like packages foreign and haven (reads and) saves a data frame as a SPSS file with the latter doing so in a tidy format - having packages that do keep your data tidy will make your life so much easier! Now we can just do the following
write_sav(drinks, "new_drinks.sav")
Now you are free to go use SPSS for some reason.
Style Guide
Following a consistent style is important for your code to be readable by you and others. The preferred style is the tidyverse style guide, though any clean and consitent styling is acceptable. Here are some packages that may help you
The lintr package will check files for style errors, though novice R users may want to hold off on using this for now.
The styler package provides functions for automatically formatting R code according to style guides and is great for beginners.
You will initially be expected to turn in a script with any submission where R is needed. Much like any writing, if your script is easy to read, then it is most likely easy to grade. A messy script without comments, spacing, and style may lead to misunderstandings. Long story short: make it look good and easy to interpret and your score will reflect that! With that said, you’ll receive a template that will hopefully be helpful.
If you want a warning about styling your script, open RStudio and go to the Tools > Global Options > Code > Diagnostics pane. Then check the box to activate style warnings. On this pane, there are other options that can be set in order to increase or decrease the amount of warnings while writing in RStudio.
Please see the discussion in R for DataScience on how tibble objects differ from base data.frame objects in how the single bracket [ is handled. ↩︎